Soroush Mehraban






InstaFlow: One Step is Enough for High-Quality Diffusion-Based Text-to-Image Generation
Soroush Mehraban
179
598
8 месяцев назад



GLIGEN (CVPR2023): Open-Set Grounded Text-to-Image Generation
Soroush Mehraban
123
411
6 месяцев назад

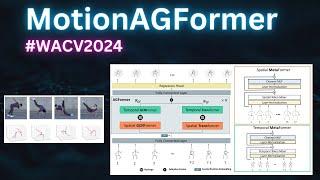
MotionAGFormer (WACV2024): Enhancing 3D Human Pose Estimation with a Transformer-GCNFormer Network
Soroush Mehraban
312
1,040
11 месяцев назад
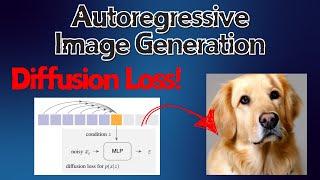

Denoising Diffusion Null-Space Model (DDNM) - Method Explained
Soroush Mehraban
96
320
54 года назад





Сейчас ищут
Soroush Mehraban
Andrey Shubin
Poya Bana
I Fşatube Tv
Holidaytuse
Shyam The Realtor
부끄러운 형들
Sean Anderson
Dr S M Haider Rizvi
Cinevasion
Ballroom Dancesport Tube
Этому Не Учат В Школе
Multifamily Investing
Best Compilation
That S A Cow Game
Jaztime Com
夹芯饼讲动漫
Diamond League Live Stream
Nicole Richards
Alyssa Framm
Rosales Recommendations
Parrot Sec Download
Blade And Sorcery Outer Rim
Математика 5
Cow Games For Babies
Youtube Shorts Must Be Stopped
Single Track Studio
Historias Assombradas
Parrot Security Edition Download
Abdur Rehman
Techsupershow
Meds Taxes
Soroush Mehraban. Смотреть видео: Vision Transformer ViT Paper Explained, HD GCN ICCV2023 Skeleton Based Action Recognition, Faster R CNN Faster Than Fast R CNN, Receptive Fields Why 3x3 Conv Layer Is The Best.